Hybrid Intelligence: Human in the loop and Eye tracking
The Attentive Eye: How Human-Centered AI is Reshaping Medical Diagnostics
1.0 Introduction: The Dual Promise and Peril of AI in Radiology
In the high-stakes field of medical imaging diagnostics, the pursuit of accuracy is relentless. Every screening represents a critical opportunity to detect disease at its earliest stage, yet this pursuit is constrained by a fundamental bottleneck in patient care: the persistent challenge of human perceptual error. This reality has fueled the rapid development of Artificial Intelligence (AI) to augment clinical expertise. However, while the promise of AI is profound, early-generation technologies often failed to solve this core problem. Their limitations created new forms of noise and friction, underscoring the urgent need for a more sophisticated, human-centered approach.
The core challenges in radiology are significant. In lung cancer screenings, for instance, a staggering 35% of lung nodules are typically missed during standard review. To mitigate such errors, Computer-Aided Diagnosis (CAD) systems were introduced, but while they could reduce some false negatives, they suffered from a critical flaw: an overwhelmingly high rate of false positives. One early system produced an average of 28 false-positive findings per scan, burying clinicians in algorithmic noise and creating an unsustainable workload. This failure established a clear mandate for a new diagnostic paradigm.
This white paper argues that the next generation of effective and trusted diagnostic AI will not be a standalone “black box” that simply offers a secondary, flawed opinion. Instead, it will be a truly collaborative system, deeply and dynamically integrated with the clinician’s own perceptual and cognitive processes. This new paradigm moves beyond merely supplementing human review and instead aims to create a symbiotic partnership where the distinct strengths of human and machine intelligence are fused to achieve a level of diagnostic precision that neither could attain alone.
To realize this vision, eye-tracking technology is emerging as the critical interface. By precisely monitoring a radiologist’s gaze, this technology provides a direct, real-time window into their attentional focus and diagnostic reasoning. This capability is proving to be the linchpin for profound advancements, not only in enhancing the performance of collaborative AI systems but also in automating the creation of expert-annotated data and validating the clinical authenticity of novel synthetic medical images. These innovations are paving the way for AI that learns from, adapts to, and truly collaborates with the human expert.
2.0 Beyond the Black Box: The Emergence of Collaborative AI
We are witnessing a strategic shift in the evolution of diagnostic AI, moving away from its role as a simple “second opinion” tool and toward its integration as a collaborative partner for the clinician. Early CAD systems operated independently, forcing radiologists to sift through a high volume of false alarms, which created friction and eroded trust. The new collaborative paradigm directly addresses this by creating a system that intelligently fuses the complementary abilities of human experts and AI algorithms, overcoming the inherent limitations of both human-only and AI-only diagnostic approaches.
An analysis of their respective capabilities reveals why this collaborative approach holds so much promise. Human radiologists and traditional CAD systems possess a natural synergy, with each excelling where the other falters.
- Human Radiologists: Exhibit exceptional specificity. Their strength lies in their ability to contextualize subtle findings, apply extensive anatomical and pathological knowledge, and effectively eliminate false positives.
- CAD Systems: Demonstrate high sensitivity. These systems excel at systematically scanning for patterns, making them highly effective at reducing false negatives by capturing tumors or lesions that might be missed by the human eye.
The concept of a collaborative CAD (C-CAD) system represents a paradigm-shifting approach designed to unify these complementary strengths. A C-CAD system leverages eye-tracking technology to monitor a radiologist’s visual search pattern in real-time. As the radiologist examines a 3D scan, the system processes their gaze to identify specific regions of interest (ROIs)—areas where their attention lingers. This gaze data serves as a direct input, guiding the AI to focus its powerful analytical capabilities only on the areas the expert has already deemed worthy of closer inspection.
A primary technical hurdle in developing such a system is the sheer volume and density of raw eye-tracking data. To make this information computationally manageable, a novel method involving graph representation and sparsification was developed. The radiologist’s gaze path is first modeled as a dense graph, then sophisticated algorithms are applied to reduce its size significantly without losing critical topological properties. This process is analogous to creating a simplified subway map from a tangled web of every possible street path—it retains the essential connections and travel patterns while discarding redundant details, making the system faster and more efficient.
Once the C-CAD system identifies ROIs from the sparsified gaze data, it deploys a 3D deep multi-task Convolutional Neural Network (CNN) to jointly perform false positive removal and segmentation. The results of this approach are striking. The C-CAD system achieved an average Dice Similarity Coefficient (DSC) of 91.5% for segmentation and 97.3% accuracy for classification (correctly identifying a lesion as a nodule versus a non-nodule). This C-CAD model provides a powerful and practical demonstration of how to move beyond inscrutable AI, creating an intelligent system that learns directly from and responds to expert human attention. However, training such sophisticated models requires vast amounts of high-quality data, which presents its own significant challenge.
3.0 Automating Expertise: Solving the Data Annotation Bottleneck
The development of robust deep learning models for medical imaging is fundamentally dependent on access to large, high-quality, and expertly annotated datasets. This dependency, however, exposes one of the greatest bottlenecks in the field: the manual annotation of medical images. This process is extraordinarily time-consuming and expensive, significantly slowing the pace of AI innovation. By one estimate, the manual annotation of just 1000 images can require a full month of dedicated work for two radiologists. This unsustainable demand for expert time necessitates a more efficient solution.
An innovative approach to solving this data bottleneck involves integrating eye-tracking and speech recognition to automate the annotation process directly within the radiologist’s existing clinical workflow. This system is designed to generate expert-labeled data passively and accurately, without adding any extra steps or burdens to the radiologist’s routine diagnostic tasks.
The methodology is elegant in its simplicity and effectiveness. As a radiologist examines a scan and dictates their findings—a standard part of clinical practice—the system correlates the precise timing of spoken keywords, such as “tumor,” “mass,” or “lesion,” with the exact location of the radiologist’s gaze on the image at that same moment. By synchronizing these two data streams, the system automatically generates a highly accurate location label for the identified pathology.
The efficacy of this automated annotation method was validated in a study on brain tumor MRIs, with compelling results:
- Labeling Accuracy: The combined eye-tracking and speech recognition system achieved 92% accuracy in correctly labeling the locations of lesions.
- Model Training Efficacy: More significantly, a deep learning network trained exclusively on these automatically generated labels was able to predict lesion locations in a completely new test set with 85% accuracy.
The strategic implication of these findings is a paradigm shift that could unlock a Moore’s Law for medical data annotation. This method transforms the largest cost center in AI development—expert time—into its most valuable asset: a continuous stream of high-quality, annotated data generated from routine clinical work. Solving the annotation bottleneck for real-world images, however, brings the next critical challenge into focus: how do we validate the authenticity of AI-generated synthetic data?
4.0 The Next Frontier: Validating Synthetic Data with Human Vision
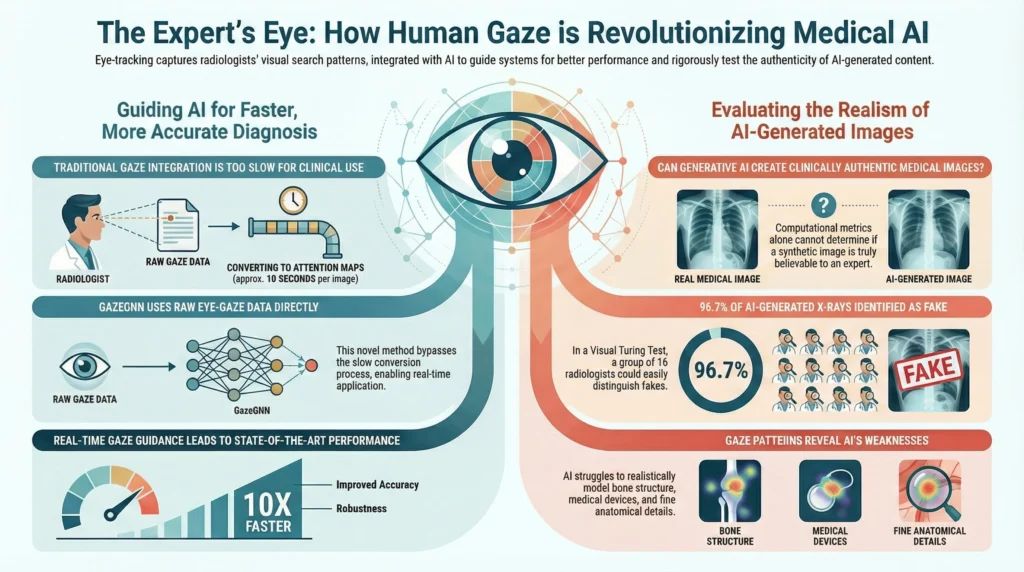
The emergence of powerful generative AI, such as Latent Diffusion Models, offers a compelling solution to persistent data challenges like patient privacy, data scarcity, and class imbalance. However, this promise is tempered by a critical problem: the computational metrics currently used to evaluate the “realism” of synthetic images often fail to align with expert human perception and clinical authenticity. An image that scores well on a mathematical metric may still contain subtle flaws that an experienced radiologist would immediately recognize as unrealistic.
To bridge this gap, the GazeVal framework was introduced as a novel methodology for evaluating synthetic medical images. GazeVal moves beyond computational metrics by using expert eye-tracking in conjunction with a Visual Turing Test (VTT), where radiologists are tasked with distinguishing between real and synthetic images.
The primary finding from the GazeVal study is striking. On an individual basis, the 16 participating radiologists demonstrated strong but imperfect performance, correctly identifying 74% of synthetic images and 86% of real ones. However, when these same experts collaborated through a voting process, their collective accuracy in identifying images as real or synthetic reached an astonishing 96.7%. This dramatic leap from individual assessment to collaborative consensus provides decisive evidence that current generative models cannot yet produce medical images that are consistently indistinguishable from real ones to the trained expert eye. It proves that collective expert judgment is almost infallible, underscoring the absolute necessity of expert-led validation over computational metrics alone.
The eye-tracking data revealed why these synthetic images fail the VTT, offering crucial insights for improving future models.
- Divergent Viewing Patterns: Quantitative metrics like Inter-Observer Congruency (IOC) revealed that radiologists employed distinct and more variable visual search strategies when interpreting synthetic images compared to real ones, likely due to the presence of subtle inconsistencies.
- Anatomical and Pathological Inconsistencies: Radiologists consistently identified unrealistic features in the synthetic images. The most common flaws were found in the rendering of bone structure, medical devices, lung parenchyma, and vascular anatomy.
- Pathology Generation Difficulty: The study found that radiologists could more easily identify a synthetic image when it contained pathologies (such as cardiomegaly or pleural effusions) compared to a normal, disease-free synthetic image. This indicates that generative models face a significantly greater challenge in realistically modeling the complex visual manifestations of disease states.
While generative AI is an undeniably powerful tool, GazeVal demonstrates that its output requires rigorous, human-centered validation to be deemed clinically reliable. Ensuring these advanced tools are ready for the clinic requires bridging the final gap to practical, real-time integration.
5.0 Bridging to Clinical Practice: Real-Time Integration and Building Trust
A key historical barrier to the clinical adoption of gaze-guided AI has been a practical one: speed. Traditional approaches required the time-consuming process of converting raw eye-tracking data into visual attention maps (VAMs)—heatmap-style representations of where a user has looked. This conversion step was too slow for the dynamic environment of a radiology reading room, making real-time application impractical.
A recent breakthrough, the GazeGNN (Gaze-guided Graph Neural Network), offers a solution. This novel architecture fundamentally advances how gaze data is processed by completely bypassing the need for VAMs. Instead, GazeGNN directly integrates raw eye-gaze data into a Graph Neural Network, creating a unified graph that simultaneously represents both the image content and the radiologist’s gaze pattern.
The improvement in efficiency achieved by GazeGNN is dramatic. A direct comparison of the time required to process gaze data for inference highlights the new architecture’s real-time capabilities.
| Architecture | Average Gaze Inference Time |
| Two-Stream (using VAMs) | 9.246 seconds |
| GazeGNN (using raw gaze) | 0.353 seconds |
This new architecture not only improves speed but also enhances model robustness. By treating gaze as a real-time input during inference, the model is not just recalling learned patterns; it is actively guided by the clinician’s attention on the new, unfamiliar image. This direct guidance helps anchor the model’s analysis to relevant features, making it more resilient when faced with data that differs from its original training set. When tested on data with such distribution shifts, the GazeGNN model experienced a significantly smaller drop in performance.
These critical advancements in speed and robustness are foundational for building clinician trust and enabling the practical integration of gaze-guided AI into the daily clinical workflow.
6.0 Conclusion: A Forward Look at Human-Centered Diagnostic AI
This analysis has charted the evolution of AI in medical diagnostics, marking a definitive shift from standalone, error-prone CAD systems to a new generation of collaborative, attentive, and human-centered intelligence. The journey beyond the “black box” has revealed that the most promising path forward is not one where machines replace human experts, but one where technology is deeply integrated with clinical expertise to create a powerful diagnostic symbiosis.
Eye-tracking has emerged as the central technology enabling this transformative shift. Its multifaceted contributions are reshaping how AI is developed, validated, and deployed in the clinic, streamlining progress across three critical domains:
- Enhancing Performance and Interpretability: By creating collaborative systems like C-CAD that leverage the combined strengths of humans and machines in real-time.
- Streamlining Development: By automating the creation of expert-annotated training data at an unprecedented scale, solving a critical industry bottleneck.
- Ensuring Reliability: By providing a rigorous, human-perceptual framework like GazeVal to validate the clinical authenticity of AI-generated data.
The question is no longer if AI will integrate into diagnostics, but how. The evidence presented here argues decisively that the only path to trustworthy and scalable adoption is through systems that see the way experts see, learn as they learn, and collaborate as a true partner, not a black box. For clinicians, researchers, and technology leaders, the path to successfully adopting AI is not about building a more powerful autonomous system but about forging a more intelligent partnership. The future belongs to deeply integrated, responsive, and trustworthy collaborative tools designed not to supplant human expertise, but to augment and amplify it.
-
GazeSAM: Interactive Image Segmentation with Eye Gaze and Segment Anything Model
-
GazeGNN: A Gaze-Guided Graph Neural Network for Chest X-ray Classification
-
Eyes Tell the Truth: GazeVal Highlights Shortcomings of Generative AI in Medical Imaging
-
Order-aware Interactive Segmentation
-
A collaborative computer aided diagnosis (C-CAD) system with eye-tracking, sparse attentional model, and deep learning
-
Integrating Eye Tracking and Speech Recognition Accurately Annotates MR Brain Images for Deep Learning: Proof of Principle
-
Comparing Dermatologist and Artificial Intelligence Heat Maps in Dermoscopic Image Analysis via Eye Tracking